众所周知界面设计一般指UI设计,下面这篇文章主要给大家介绍了关于Yolov5(v5.0)+pyqt5界面设计的相关资料,文中通过图文以及实例代码介绍的非常详细,需要的朋友可以参考下
1.下载安装pyqt5工具包以及配置ui界面开发环境
pip install PyQt5 pip install PyQt5-tools
2.点击File->Settings->External Tools进行工具添加,依次进行Qt Designer、PyUIC环境配置.
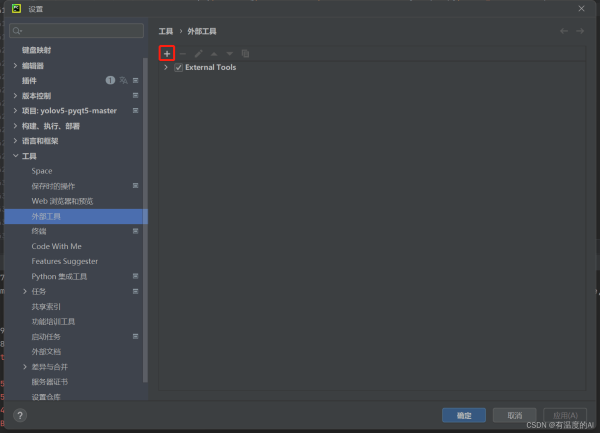
2.1 添加QtDesigner
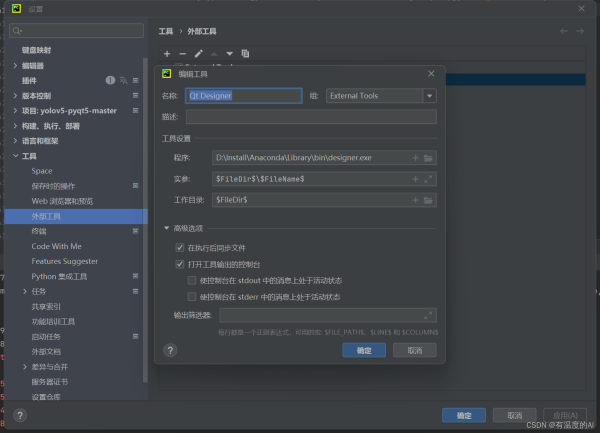
Qt Designer 是通过拖拽的方式放置控件,并实时查看控件效果进行快速UI设计
| 位置 | 内容 |
| name | 可以随便命名,只要便于记忆就可以,本次采取通用命名:Qt Designer |
| Program | designer.exe路径,一般在python中.\Library\bin\designer.exe |
| Arguments | 固定格式,直接复制也可:$FileDir$\$FileName$ |
| Working directory | 固定格式,直接复制也可:$FileDir$ |
2.2 添加PyUIC

PyUIC主要是把Qt Designer生成的.ui文件换成.py文件
| 位置 | 内容 |
| name | 可以随便命名,只要便于记忆就可以,本次采取通用命名:PyUiC |
| Program | python.exe路径,一般在python安装根目录中 |
| Arguments | 固定格式,直接复制也可:-m PyQt5.uic.pyuic $FileName$ -o $FileNameWithoutExtension$.py |
| Working directory | 固定格式,直接复制也可:$FileDir$ |
3. QtDesigner建立图形化窗口界面
3.1 在根目录下新建UI文件夹进行UI文件的专门存储
点击Tools->External Tools->Qt Designer进行图形界面创建.

3.2 创建一个Main Window窗口



3.3 完成基本界面开发后,保存其为Detect.ui,放置在UI文件夹下,利用PyUic工具将其转化为Detect.py文件。


转换完成后,进行相应的槽函数的建立与修改,此处建议直接看我后面给出的demo。
4. demo
使用时只需将parser.add_argument中的'--weights'设为响应权重即可。
# -*- coding: utf-8 -*- # Form implementation generated from reading ui file '.\project.ui' # # Created by: PyQt5 UI code generator 5.9.2 # # WARNING! All changes made in this file will be lost! import sys import cv2 import argparse import random import torch import numpy as np import torch.backends.cudnn as cudnn from PyQt5 import QtCore, QtGui, QtWidgets from utils.torch_utils import select_device from models.experimental import attempt_load from utils.general import check_img_size, non_max_suppression, scale_coords from utils.datasets import letterbox from utils.plots import plot_one_box class Ui_MainWindow(QtWidgets.QMainWindow): def __init__(self, parent=None): super(Ui_MainWindow, self).__init__(parent) self.timer_video = QtCore.QTimer() self.setupUi(self) self.init_logo() self.init_slots() self.cap = cv2.VideoCapture() self.out = None # self.out = cv2.VideoWriter('prediction.avi', cv2.VideoWriter_fourcc(*'XVID'), 20.0, (640, 480)) parser = argparse.ArgumentParser() parser.add_argument('--weights', nargs='+', type=str, default='weights/best.pt', help='model.pt path(s)') # file/folder, 0 for webcam parser.add_argument('--source', type=str, default='data/images', help='source') parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)') parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold') parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS') parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') parser.add_argument( '--view-img', action='store_true', help='display results') parser.add_argument('--save-txt', action='store_true', help='save results to *.txt') parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels') parser.add_argument('--nosave', action='store_true', help='do not save images/videos') parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3') parser.add_argument( '--agnostic-nms', action='store_true', help='class-agnostic NMS') parser.add_argument('--augment', action='store_true', help='augmented inference') parser.add_argument('--update', action='store_true', help='update all models') parser.add_argument('--project', default='runs/detect', help='save results to project/name') parser.add_argument('--name', default='exp', help='save results to project/name') parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment') self.opt = parser.parse_args() print(self.opt) source, weights, view_img, save_txt, imgsz = self.opt.source, self.opt.weights, self.opt.view_img, self.opt.save_txt, self.opt.img_size self.device = select_device(self.opt.device) self.half = self.device.type != 'cpu' # half precision only supported on CUDA cudnn.benchmark = True # Load model self.model = attempt_load( weights, map_location=self.device) # load FP32 model stride = int(self.model.stride.max()) # model stride self.imgsz = check_img_size(imgsz, s=stride) # check img_size if self.half: self.model.half() # to FP16 # Get names and colors self.names = self.model.module.names if hasattr( self.model, 'module') else self.model.names self.colors = [[random.randint(0, 255) for _ in range(3)] for _ in self.names] def setupUi(self, MainWindow): MainWindow.setObjectName("MainWindow") MainWindow.resize(800, 600) self.centralwidget = QtWidgets.QWidget(MainWindow) self.centralwidget.setObjectName("centralwidget") self.pushButton = QtWidgets.QPushButton(self.centralwidget) self.pushButton.setGeometry(QtCore.QRect(20, 130, 112, 34)) self.pushButton.setObjectName("pushButton") self.pushButton_2 = QtWidgets.QPushButton(self.centralwidget) self.pushButton_2.setGeometry(QtCore.QRect(20, 220, 112, 34)) self.pushButton_2.setObjectName("pushButton_2") self.pushButton_3 = QtWidgets.QPushButton(self.centralwidget) self.pushButton_3.setGeometry(QtCore.QRect(20, 300, 112, 34)) self.pushButton_3.setObjectName("pushButton_3") self.groupBox = QtWidgets.QGroupBox(self.centralwidget) self.groupBox.setGeometry(QtCore.QRect(160, 90, 611, 411)) self.groupBox.setObjectName("groupBox") self.label = QtWidgets.QLabel(self.groupBox) self.label.setGeometry(QtCore.QRect(10, 40, 561, 331)) self.label.setObjectName("label") self.textEdit = QtWidgets.QTextEdit(self.centralwidget) self.textEdit.setGeometry(QtCore.QRect(150, 10, 471, 51)) self.textEdit.setObjectName("textEdit") MainWindow.setCentralWidget(self.centralwidget) self.menubar = QtWidgets.QMenuBar(MainWindow) self.menubar.setGeometry(QtCore.QRect(0, 0, 800, 30)) self.menubar.setObjectName("menubar") MainWindow.setMenuBar(self.menubar) self.statusbar = QtWidgets.QStatusBar(MainWindow) self.statusbar.setObjectName("statusbar") MainWindow.setStatusBar(self.statusbar) self.retranslateUi(MainWindow) QtCore.QMetaObject.connectSlotsByName(MainWindow) def retranslateUi(self, MainWindow): _translate = QtCore.QCoreApplication.translate MainWindow.setWindowTitle(_translate("MainWindow", "演示系统")) self.pushButton.setText(_translate("MainWindow", "图片检测")) self.pushButton_2.setText(_translate("MainWindow", "摄像头检测")) self.pushButton_3.setText(_translate("MainWindow", "视频检测")) self.groupBox.setTitle(_translate("MainWindow", "检测结果")) self.label.setText(_translate("MainWindow", "TextLabel")) self.textEdit.setHtml(_translate("MainWindow", "\n" "\n" "演示系统
")) def init_slots(self): self.pushButton.clicked.connect(self.button_image_open) self.pushButton_3.clicked.connect(self.button_video_open) self.pushButton_2.clicked.connect(self.button_camera_open) self.timer_video.timeout.connect(self.show_video_frame) def init_logo(self): pix = QtGui.QPixmap('wechat.jpg-600') self.label.setScaledContents(True) self.label.setPixmap(pix) def button_image_open(self): print('button_image_open') name_list = [] img_name, _ = QtWidgets.QFileDialog.getOpenFileName( self, "打开图片", "", "*.jpg-600;;*.png-600;;All Files(*)") if not img_name: return img = cv2.imread(img_name) print(img_name) showimg = img with torch.no_grad(): img = letterbox(img, new_shape=self.opt.img_size)[0] # Convert # BGR to RGB, to 3x416x416 img = img[:, :, ::-1].transpose(2, 0, 1) img = np.ascontiguousarray(img) img = torch.from_numpy(img).to(self.device) img = img.half() if self.half else img.float() # uint8 to fp16/32 img /= 255.0 # 0 - 255 to 0.0 - 1.0 if img.ndimension() == 3: img = img.unsqueeze(0) # Inference pred = self.model(img, augment=self.opt.augment)[0] # Apply NMS pred = non_max_suppression(pred, self.opt.conf_thres, self.opt.iou_thres, classes=self.opt.classes, agnostic=self.opt.agnostic_nms) print(pred) # Process detections for i, det in enumerate(pred): if det is not None and len(det): # Rescale boxes from img_size to im0 size det[:, :4] = scale_coords( img.shape[2:], det[:, :4], showimg.shape).round() for *xyxy, conf, cls in reversed(det): label = '%s %.2f' % (self.names[int(cls)], conf) name_list.append(self.names[int(cls)]) plot_one_box(xyxy, showimg, label=label, color=self.colors[int(cls)], line_thickness=2) cv2.imwrite('prediction.jpg-600', showimg) self.result = cv2.cvtColor(showimg, cv2.COLOR_BGR2BGRA) self.result = cv2.resize( self.result, (640, 480), interpolation=cv2.INTER_AREA) self.QtImg = QtGui.QImage( self.result.data, self.result.shape[1], self.result.shape[0], QtGui.QImage.Format_RGB32) self.label.setPixmap(QtGui.QPixmap.fromImage(self.QtImg)) def button_video_open(self): video_name, _ = QtWidgets.QFileDialog.getOpenFileName( self, "打开视频", "", "*.mp4;;*.avi;;All Files(*)") if not video_name: return flag = self.cap.open(video_name) if flag == False: QtWidgets.QMessageBox.warning( self, u"Warning", u"打开视频失败", buttons=QtWidgets.QMessageBox.Ok, defaultButton=QtWidgets.QMessageBox.Ok) else: self.out = cv2.VideoWriter('prediction.avi', cv2.VideoWriter_fourcc( *'MJPG'), 20, (int(self.cap.get(3)), int(self.cap.get(4)))) self.timer_video.start(30) self.pushButton_3.setDisabled(True) self.pushButton.setDisabled(True) self.pushButton_2.setDisabled(True) def button_camera_open(self): if not self.timer_video.isActive(): # 默认使用第一个本地camera flag = self.cap.open(0) if flag == False: QtWidgets.QMessageBox.warning( self, u"Warning", u"打开摄像头失败", buttons=QtWidgets.QMessageBox.Ok, defaultButton=QtWidgets.QMessageBox.Ok) else: self.out = cv2.VideoWriter('prediction.avi', cv2.VideoWriter_fourcc( *'MJPG'), 20, (int(self.cap.get(3)), int(self.cap.get(4)))) self.timer_video.start(30) self.pushButton_3.setDisabled(True) self.pushButton.setDisabled(True) self.pushButton_2.setText(u"关闭摄像头") else: self.timer_video.stop() self.cap.release() self.out.release() self.label.clear() self.init_logo() self.pushButton_3.setDisabled(False) self.pushButton.setDisabled(False) self.pushButton_2.setText(u"摄像头检测") def show_video_frame(self): name_list = [] flag, img = self.cap.read() if img is not None: showimg = img with torch.no_grad(): img = letterbox(img, new_shape=self.opt.img_size)[0] # Convert # BGR to RGB, to 3x416x416 img = img[:, :, ::-1].transpose(2, 0, 1) img = np.ascontiguousarray(img) img = torch.from_numpy(img).to(self.device) img = img.half() if self.half else img.float() # uint8 to fp16/32 img /= 255.0 # 0 - 255 to 0.0 - 1.0 if img.ndimension() == 3: img = img.unsqueeze(0) # Inference pred = self.model(img, augment=self.opt.augment)[0] # Apply NMS pred = non_max_suppression(pred, self.opt.conf_thres, self.opt.iou_thres, classes=self.opt.classes, agnostic=self.opt.agnostic_nms) # Process detections for i, det in enumerate(pred): # detections per image if det is not None and len(det): # Rescale boxes from img_size to im0 size det[:, :4] = scale_coords( img.shape[2:], det[:, :4], showimg.shape).round() # Write results for *xyxy, conf, cls in reversed(det): label = '%s %.2f' % (self.names[int(cls)], conf) name_list.append(self.names[int(cls)]) print(label) plot_one_box( xyxy, showimg, label=label, color=self.colors[int(cls)], line_thickness=2) self.out.write(showimg) show = cv2.resize(showimg, (640, 480)) self.result = cv2.cvtColor(show, cv2.COLOR_BGR2RGB) showImage = QtGui.QImage(self.result.data, self.result.shape[1], self.result.shape[0], QtGui.QImage.Format_RGB888) self.label.setPixmap(QtGui.QPixmap.fromImage(showImage)) else: self.timer_video.stop() self.cap.release() self.out.release() self.label.clear() self.pushButton_3.setDisabled(False) self.pushButton.setDisabled(False) self.pushButton_2.setDisabled(False) self.init_logo() if __name__ == '__main__': app = QtWidgets.QApplication(sys.argv) ui = Ui_MainWindow() ui.show() sys.exit(app.exec_())
5.添加背景图片
将demo中最后一段代码改为如下,其中background-image为背景图片地址。
if __name__ == '__main__': stylesheet = """ Ui_MainWindow { background-image: url("4K.jpg-600"); background-repeat: no-repeat; background-position: center; } """ app = QtWidgets.QApplication(sys.argv) app.setStyleSheet(stylesheet) ui = Ui_MainWindow() ui.show() sys.exit(app.exec_())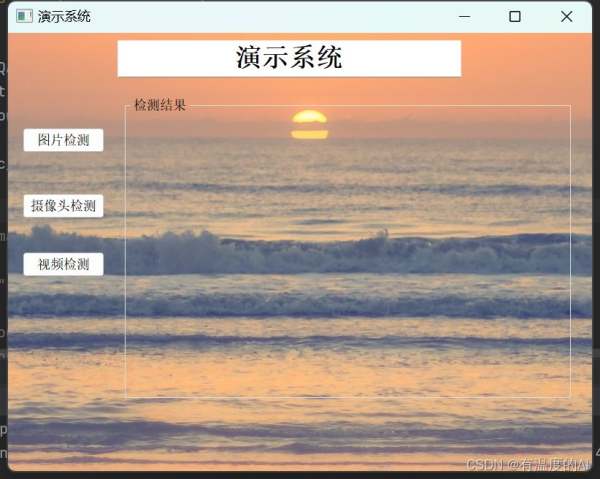
6.reference
总结
到此这篇关于Yolov5(v5.0)+pyqt5界面设计的文章就介绍到这了,更多相关Yolov5+pyqt5界面设计内容请搜索0133技术站以前的文章或继续浏览下面的相关文章希望大家以后多多支持0133技术站!
以上就是Yolov5(v5.0)+pyqt5界面设计图文教程的详细内容,更多请关注0133技术站其它相关文章!








