这篇文章主要介绍了elasticsearch安装以及部署教程,内涵详细的图文展示与案例介绍,能够帮助你从0成功部署这个框架,需要的朋友可以参考下
1 概述
1.1 Elastic Stack的核心
The Elastic Stack,包括ElasticSearch,Kibana,Beats和Logstash(也称为ELK Stack)
能够安全可靠的获取任何来源,任何格式的数据,然后实时的对诗句进行搜索,分析和可视化
Elasticsearch,简称ES,ES是一个开源的高扩展的分布式全文搜索引擎
是整个Elastic Stack技术栈的核心,它可以近乎实时的存储,检索数据
1.2 Elasticsearch And Solr(对比图)
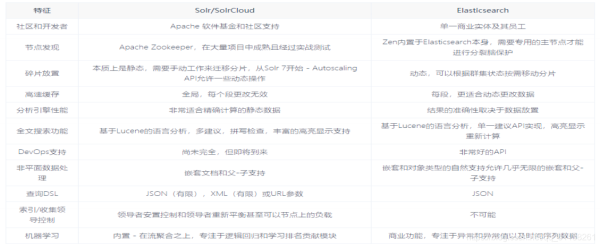
2 入门
2.1 安装
直接进入bin目录启动
9300端口为Elasticsearch集群间组件的通信端口
9200 端口为浏览器访问的 http协议 RESTful 端口
浏览器访问: localhost:9200
2.2 数据格式
将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比
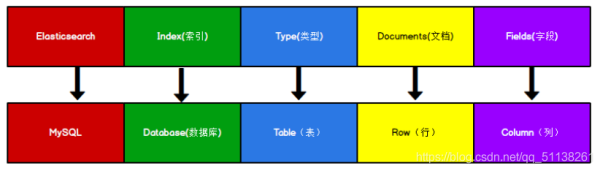
Elasticsearch 7.X 中, Type 的概念已经被删除了
2.3 java操作api
3 环境
3.1 Linux单机版
#解压 tar -zxf elasticsearch-7.8.0-linux-x86_64.tar.gz #移动 mv elasticsearch-7.8.0 /opt/ #创建用户(es不能用root用户启动) adduser chen #修改文件所有者 chown -R chen /opt/elasticsearch-7.8.0/ #进入配置文件目录 cd /opt/elasticsearch-7.8.0/config/ #修改配置文件 vim elasticsearch.yml
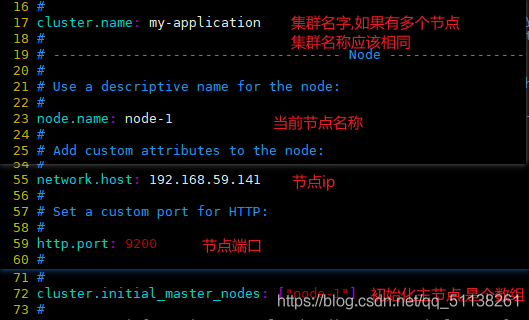
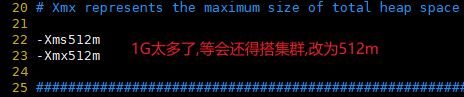
#修改内存占用 vim jvm.options
#修改系统配置 vim /etc/security/limits.conf #在文件末尾中增加下面内容 #nproc : 是操作系统级别对每个用户创建的进程数的限制 #nofile : 是每个进程可以打开的文件数的限制 # 每个进程可以打开的文件数的限制( * ,代表所有用户,也可以是具体的某一个用户) * soft nproc 65536 * hard nproc 65536 * soft nofile 65536 * hard nofile 65536 #修改系统配置 #操作系统级别对每个用户创建的进程数的限制 vim /etc/security/limits.d/20-nproc.conf #文件末尾同样添加 * soft nproc 65536 * hard nproc 65536 * soft nofile 65536 * hard nofile 65536 #修改系统配置 vim /etc/sysctl.conf # 在文件中增加下面内容 # 一个进程可以拥有的 VMA(虚拟内存区域)的数量,默认值为 65536 vm.max_map_count=655360 #重新加载 sysctl -p #进入bin目录 cd /opt/elasticsearch-7.8.0/bin/ #使用用户chen启动es su chen ./elasticsearch #如果报错,再执行一遍 chown -R chen /opt/elasticsearch-7.8.0/
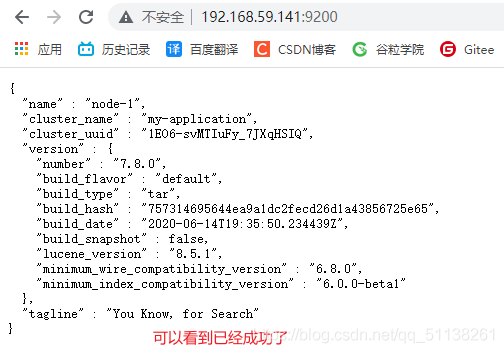
3.2 Linux集群部署
| 节点 | ip |
|---|---|
| es-node01 | 192.168.59.141 |
| es-node02 | 192.168.59.142 |
| es-node03 | 192.168.59.143 |
就用刚刚的es环境,在上面进行修改
#进入配置文件夹 cd /opt/elasticsearch-7.8.0/config/ #编辑配置文件 vim elasticsearch.yml #全部删除 ggvGd
替换成以下内容
#集群名称 cluster.name: es-cluster #节点名称,每个节点的名称不能重复 node.name: es-node01 #ip 地址,每个节点的地址不能重复 network.host: es-node01 #是不是有资格主节点 node.master: true node.data: true http.port: 9200 transport.tcp.port: 9300 #head 插件需要这打开这两个配置 http.cors.allow-origin: "*" http.cors.enabled: true http.max_content_length: 200mb #es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master cluster.initial_master_nodes: ["es-node01"] #es7.x 之后新增的配置,节点发现 discovery.seed_hosts: ["es-node01:9300","es-node02:9300","es-node03:9300"] gateway.recover_after_nodes: 2 network.tcp.keep_alive: true network.tcp.no_delay: true transport.tcp.compress: true #集群内同时启动的数据任务个数,默认是 2 个 cluster.routing.allocation.cluster_concurrent_rebalance: 16 #添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个 cluster.routing.allocation.node_concurrent_recoveries: 16 #初始化数据恢复时,并发恢复线程的个数,默认 4 个 cluster.routing.allocation.node_initial_primaries_recoveries: 16
修改hosts文件
cat >> /etc/hosts << EOF 192.168.59.141 es-node01 192.168.59.142 es-node02 192.168.59.143 es-node03 EOF
拿当前Linux服务器作为范本,克隆两台虚拟机(完整克隆)
开机分别修改服务器ip(142 and 143)
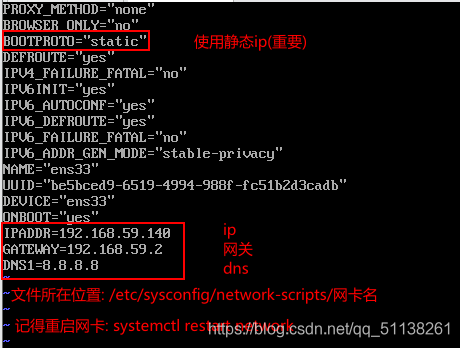
设置主机名(分别设置)
hostnamectl set-hostname es-node01 hostnamectl set-hostname es-node02 hostnamectl set-hostname es-node03
修改node02 and node03的节点名称和ip
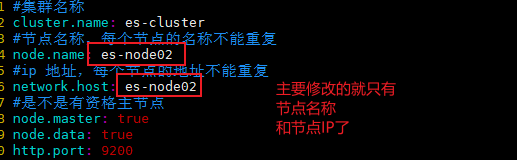
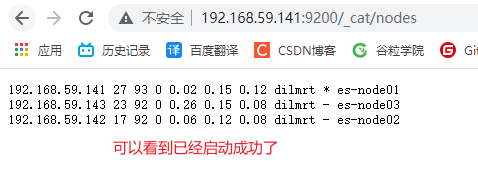
因为是克隆来的,所以前面的些新增用户,修改系统配置,给权限什么的也被继承过来了,现在只需要启动服务即可
3.1 elasticsearch-head chrome插件安装
下载压缩包,解压。
接着点击Chrome右上角选项->工具->管理扩展(或则地址栏输入chrome://extensions/),选择打开“开发者模式”,让后点击“加载已解压得扩展程序”,选择elasticsearch-head/_site,即可完成chrome插件安装。
3.2 kibana安装
进入config目录,文件末尾添加
#默认端口 server.port: 5601 #es服务器地址 elasticsearch.hosts: ["http://localhost:9200"] #索引名 kibana.index: ".kibana" #中文 i18n.locale: "zh-CN"
进入bin目录启动
到此这篇关于elasticsearch安装以及部署教程的文章就介绍到这了,更多相关elasticsearch框架部署内容请搜索html中文网以前的文章或继续浏览下面的相关文章希望大家以后多多支持html中文网!
以上就是Java elasticsearch安装以及部署教程的详细内容,更多请关注0133技术站其它相关文章!







