这篇文章主要为大家详细介绍了Python数据分析中的词频统计和词云图可视化,文中的示例代码讲解详细,对我们学习Python有一定的帮助,需要的可以参考一下
一:安装必要的库
导入必要的库
import collections # 词频统计库 import os import re # 正则表达式库 import urllib.error # 指定url,获取网页数据 import urllib.request import jieba # 结巴分词 import matplotlib.pyplot as plt # 图像展示库 import numpy as np # numpy数据处理库 import pandas as pd import wordcloud # 词云展示库 import xlwt # 进行excel操作 from PIL import Image # 图像处理库 from bs4 import BeautifulSoup # 网页解析,获取数据 from pyecharts.charts import Bar # 画柱形图
导入的库,如果出现报错,自己安装即可
如下安装示例1
pip install xlrd -i https://pypi.tuna.tsinghua.edu.cn/simple

如下安装示例2
词云库下载,需要注意查看自己版本,下载对应版本安装
https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud

如博主使用的是python3.7,64位,【可以调出cmd 输入python回车即可查看】

总之,安装必要的库,比较简单,这边不过多阐述
二:数据分析 条形图可视化
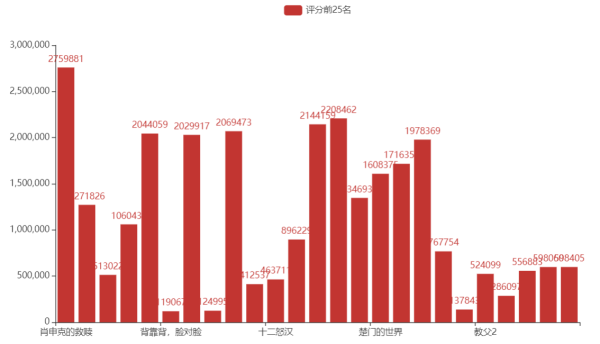
电影评分前25名,条形图展示
# 可视化 data = pd.read_excel('豆瓣电影Top250.xls') df = data.sort_values('评分', ascending=False).head(25) v = df['影片中文名'].values.tolist() # tolist()将数据转换为列表形式 d = df['评分'].values.tolist() # 设置颜色 color_series = ['#2C6BA0', '#2B55A1', '#2D3D8E', '#44388E', '#6A368B' '#7D3990', '#A63F98', '#C31C88', '#D52178', '#D5225B'] print("-----" * 15) bar = ( Bar() .add_xaxis([i for i in df['影片中文名'].values.tolist()]) .add_yaxis('评分前25名', df['评价数'].values.tolist()) ) bar.render("./条形图.html") print("柱形图保存成功!")生成html网页可以查看条形图 电影评分前25名
三:数据分析 词频统计 词云图可视化
# 读取文件 fn = open('top250.txt', 'r', encoding='utf-8') string_data = fn.read() fn.close() 需要特别注意的是,文件格式为utf8,可对txt另存为,再设置编码格式,如下

词频统计 词云图生成 :
# 读取文件 fn = open('top250.txt', 'r', encoding='utf-8') string_data = fn.read() fn.close() # 文本预处理 pattern = re.compile(u'\t|\n|\.|-|:|;|\)|\(|\?|"') # 定义正则表达式匹配模式 string_data = re.sub(pattern, '', string_data) # 将符合模式的字符去除 # 文本分词 seg_list_exact = jieba.cut(string_data, cut_all=False) # 精确模式分词 object_list = [] remove_words = [u'19', u',', u'20', u'德国', u'导演', u'日本', u'法国', u'等', u'能', u'都', u'。', u' ', u'、', u'中', u'在', u'了', u'20', u'大陆', u'我们', u'美国'] # 自定义去除词库 for word in seg_list_exact: # 循环读出每个分词 if word not in remove_words: # 如果不在去除词库中 object_list.append(word) # 分词追加到列表 # 词频统计 word_counts = collections.Counter(object_list) word_counts_top10 = word_counts.most_common(10) print(word_counts_top10) # 输出检查 word_counts_top10 = str(word_counts_top10) # 词频展示 mask = np.array(Image.open('image.jpg-600')) wc = wordcloud.WordCloud( font_path='simfang.ttf', mask=mask, max_words=100, # 最多显示词数 max_font_size=150, # 字体最大值 background_color='white', width=800, height=600, ) wc.generate_from_frequencies(word_counts) plt.imshow(wc) plt.axis('off') plt.show() wc.to_file('wordcloud.png-600')运行测试,实现词频统计


同时生成词云图 保存本地可查看

完整源码分享,需要自取
import collections # 词频统计库 import os import re # 正则表达式库 import urllib.error # 指定url,获取网页数据 import urllib.request import jieba # 结巴分词 import matplotlib.pyplot as plt # 图像展示库 import numpy as np # numpy数据处理库 import pandas as pd import wordcloud # 词云展示库 import xlwt # 进行excel操作 from PIL import Image # 图像处理库 from bs4 import BeautifulSoup # 网页解析,获取数据 from pyecharts.charts import Bar # 画柱形图 def main(): baseurl = "https://movie.douban.com/top250?start=" # 获取网页 datalist = getDate(baseurl) savepath = ".\\豆瓣电影Top250.xls" # 保存数据 saveData(datalist, savepath) head = { "User-Agent": "Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 85.0.4183.121Safari / 537.36" } # 影片详情链接规则 findLink = re.compile(r'') # 创建正则表达式对象 # 影片图片的链接 findImgSrc = re.compile(r'(.*)') # 影片评分 findRating = re.compile(r'') # 评价人数 findJudge = re.compile(r'(\d*)人评价') # 概况 findInq = re.compile(r'(.*)') # 找到影片的相关内容 findBd = re.compile(r'(.*?)
', re.S) # 爬取网页 def getDate(baseurl): datalist = [] x = 1 # 调用获取页面信息的函数(10次) for i in range(0, 10): url = baseurl + str(i * 25) html = askURL(url) # 保存获取到的网页源码 # 逐一解析数据 soup = BeautifulSoup(html, "html.parser") for item in soup.find_all('div', class_="item"): data = [] # 保存一部电影的所有信息 item = str(item) # 将item转换为字符串 # 影片详情链接 link = re.findall(findLink, item)[0] # 追加内容到列表 data.append(link) imgSrc = re.findall(findImgSrc, item)[0] data.append(imgSrc) titles = re.findall(findTitle, item) if (len(titles) == 2): ctitle = titles[0] data.append(ctitle) # 添加中文名 otitle = titles[1].replace("/", "") data.append(otitle) # 添加外国名 else: data.append(titles[0]) data.append(' ') # 外国名如果没有则留空 rating = re.findall(findRating, item)[0] data.append(rating) judgeNum = re.findall(findJudge, item)[0] data.append(judgeNum) inq = re.findall(findInq, item) if len(inq) != 0: inq = inq[0].replace("。", "") data.append(inq) else: data.append(' ') bd = re.findall(findBd, item)[0] bd = re.sub(' 到此这篇关于Python实现词云图词频统计的文章就介绍到这了,更多相关Python词云图词频统计内容请搜索0133技术站以前的文章或继续浏览下面的相关文章希望大家以后多多支持0133技术站!
以上就是Python实现词云图词频统计的详细内容,更多请关注0133技术站其它相关文章!








