itertools是python内置的模块,使用简单且功能强大。这篇文章主要为大家详细介绍了itertools模块的使用方法,感兴趣的小伙伴可以了解一下
itertools — 为高效循环而创建迭代器的函数
accumulate(iterable: Iterable, func: None, initial:None)
iterable:需要操作的可迭代对象
func:对可迭代对象需要操作的函数,必须包含两个参数
initial: 累加的开始值
对可迭代对象进行累计或者通过func实现双目运算,当指定func的时候需要两个参数。返回的是迭代器,与这个方法类似的就是functools下的reduce,reduce和accumulate都是累计进行操作,不同的是reduce只会返回最后的元素,而accumulate会显示所有的元素,包含中间的元素,对比如下:
| 区别 | reduce | accumulate |
|---|---|---|
| 返回值 | 返回的是一个元素 | 返回的是一个迭代器(包含中间处理的元素) |
| 所属模块 | functools | itertools |
| 性能 | 略差 | 比reduce好一些 |
| 初始值 | 可以设置初始值 | 可以设置初始值 |
import time from itertools import accumulate from functools import reduce l_data = [1, 2, 3, 4] data = accumulate(l_data, lambda x, y: x + y, initial=2) print(list(data)) start = time.time() for i in range(100000): data = accumulate(l_data, lambda x, y: x + y, initial=2) print(time.time() - start) start = time.time() for i in range(100000): data = reduce(lambda x, y: x + y, l_data) print(time.time() - start) #输出 [2, 3, 5, 8, 12] 0.027924537658691406 0.03989362716674805
由上述结果可知,accumulate比reduce性能稍好一些,而且还能输出中间的处理过程。
chain(*iterables)
iterables:接收多个可迭代对象
依次返回多个迭代对象的元素,返回的是一个迭代器,对于字典输出元素时,默认会输出字典的key
from itertools import chain import time list_data = [1, 2, 3] dict_data = {"a": 1, "b": 2} set_data = {4, 5, 6} print(list(chain(list_data, dict_data, set_data))) list_data = [1, 2, 3] list_data2 = [4, 5, 6] start = time.time() for i in range(100000): chain(list_data, list_data2) print(time.time() - start) start = time.time() for i in range(100000): list_data.extend(list_data2) print(time.time() - start) #输出 [1, 2, 3, 'a', 'b', 4, 5, 6] 0.012955427169799805 0.013965129852294922 combinations(iterable: Iterable, r)
iterable:需要操作的可迭代对象
r: 抽取的子序列元素的个数
操作可迭代对象,根据所需抽取的子序列个数返回子序列,子序列中的元素也是有序、不可重复并且是以元组的形式呈现的。
from itertools import combinations data = range(5) print(tuple(combinations(data, 2))) str_data = "asdfgh" print(tuple(combinations(str_data, 2))) #输出 ((0, 1), (0, 2), (0, 3), (0, 4), (1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4)) (('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'g'), ('f', 'h'), ('g', 'h')) combinations_with_replacement(iterable: Iterable, r)
与上述的combinations(iterable: Iterable, r)类似,不过区别在于,combinations_with_replacement的子序列的元素可以重复,也是有序的,具体如下:
from itertools import combinations_with_replacement data = range(5) print(tuple(combinations_with_replacement(data, 2))) str_data = "asdfgh" print(tuple(combinations_with_replacement(str_data, 2))) #输出 ((0, 0), (0, 1), (0, 2), (0, 3), (0, 4), (1, 1), (1, 2), (1, 3), (1, 4), (2, 2), (2, 3), (2, 4), (3, 3), (3, 4), (4, 4)) (('a', 'a'), ('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 's'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'd'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'f'), ('f', 'g'), ('f', 'h'), ('g', 'g'), ('g', 'h'), ('h', 'h')) compress(data: Iterable, selectors: Iterable)
data:需要操作的可迭代对象
selectors:判断真值的可迭代对象,不能时str,最好是列表、元组、之类的
根据selectors中的元素是否为true来输出data中对应索引的元素,以最短的为准,返回一个迭代器。
from itertools import compress data = "asdfg" list_data = [1, 0, 0, 0, 1, 4] print(list(compress(data, list_data))) #输出 ['a', 'g']
count(start, step)
start: 开始的元素
step: 自开始元素增长的步长
返回一个迭代器,从start按照步长递增,不会一次性生成,最好使用next()进行元素的递归的获取。
from itertools import count c = count(start=10, step=20) print(next(c)) print(next(c)) print(next(c)) print(next(c)) print(c) #输出 10 30 50 70 count(90, 20)
cycle(iterable)
iterable: 需要循环输出的可迭代对象
返回一个迭代器,循环输出可迭代对象的元素。于count一样,最好不要将结果转换为可迭代对象,因为是循环,所以建议使用next()或者for循环获取元素。
from itertools import cycle a = "asdfg" data = cycle(a) print(next(data)) print(next(data)) print(next(data)) print(next(data)) #输出 a s d f
dropwhile(predicate, iterable)
predicate:是否舍弃元素的标准
iterable: 可迭代对象
返回一个迭代器,根据predicate是否为True来舍弃元素。当predicate为False时,后面的元素不管是否为True都会输出。
from itertools import dropwhile list_data = [1, 2, 3, 4, 5] print(list(dropwhile(lambda i: i <3, list_data))) print(list(dropwhile(lambda x: x <5, [1, 4, 6, 4, 1]))) #输出 [3, 4, 5] [6, 4, 1]
filterfalse(predicate, iterable)
predicate:是否舍弃元素的标准
iterable: 可迭代对象
返回一个迭代器, 根据predicate是否为False判断输出,对所有元素进行操作。类似于filter方法,但是是filter的相反的.
import time from itertools import filterfalse print(list(filterfalse(lambda i: i % 2 == 0, range(10)))) start = time.time() for i in range(100000): filterfalse(lambda i: i % 2 == 0, range(10)) print(time.time() - start) start = time.time() for i in range(100000): filter(lambda i: i % 2 == 0, range(10)) print(time.time() - start) #输出 [1, 3, 5, 7, 9] 0.276653528213501 0.2768676280975342
由上述结果看出,filterfalse与filter性能相差不大
groupby(iterable, key=None)
iterable: 可迭代对象
key: 可选,需要对元素进行判断的条件, 默认为x == x。
返回一个迭代器,根据key返回连续的键和组(连续符合key条件的元素)。
注意使用groupby进行分组前需要对其进行排序。
from itertools import groupby str_data = "babada" for k, v in groupby(str_data): print(k, list(v)) str_data = "aaabbbcd" for k, v in groupby(str_data): print(k, list(v)) def func(x: str): print(x) return x.isdigit() str_data = "12a34d5" for k, v in groupby(str_data, key=func): print(k, list(v)) #输出 b ['b'] a ['a'] b ['b'] a ['a'] d ['d'] a ['a'] a ['a', 'a', 'a'] b ['b', 'b', 'b'] c ['c'] d ['d'] 1 2 a True ['1', '2'] 3 False ['a'] 4 d True ['3', '4'] 5 False ['d'] True ['5']
islice(iterable, stop)\islice(iterable, start, stop[, step])
iterable: 需要操作的可迭代对象
start: 开始操作的索引位置
stop: 结束操作的索引位置
step: 步长
返回一个迭代器。类似于切片,但是其索引不支持负数。
from itertools import islice import time list_data = [1, 5, 4, 2, 7] #学习中遇到问题没人解答?小编创建了一个Python学习交流群:725638078 start = time.time() for i in range(100000): data = list_data[:2:] print(time.time() - start) start = time.time() for i in range(100000): data = islice(list_data, 2) print(time.time() - start) print(list(islice(list_data, 1, 3))) print(list(islice(list_data, 1, 4, 2))) #输出 0.010963201522827148 0.01595783233642578 [5, 4] [5, 2] 0.010963201522827148 0.01595783233642578 [5, 4] [5, 2]
由上述结果可以看出,切片性能比islice性能稍好一些。
pairwise(iterable)
需要操作的可迭代对象
返回一个迭代器, 返回可迭代对象中的连续重叠对,少于两个返回空。
from itertools import pairwise str_data = "asdfweffva" list_data = [1, 2, 5, 76, 8] print(list(pairwise(str_data))) print(list(pairwise(list_data))) #输出 [('a', 's'), ('s', 'd'), ('d', 'f'), ('f', 'w'), ('w', 'e'), ('e', 'f'), ('f', 'f'), ('f', 'v'), ('v', 'a')] [(1, 2), (2, 5), (5, 76), (76, 8)] permutations(iterable, r=None)
iterable: 需要操作的可迭代对象
r: 抽取的子序列
与combinations类似,都是抽取可迭代对象的子序列,不过,permutations是不可重复,无序的, 与combinations_with_replacement刚好相反。
from itertools import permutations data = range(5) print(tuple(permutations(data, 2))) str_data = "asdfgh" print(tuple(permutations(str_data, 2))) #输出 ((0, 1), (0, 2), (0, 3), (0, 4), (1, 0), (1, 2), (1, 3), (1, 4), (2, 0), (2, 1), (2, 3), (2, 4), (3, 0), (3, 1), (3, 2), (3, 4), (4, 0), (4, 1), (4, 2), (4, 3)) (('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 'a'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'a'), ('d', 's'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'a'), ('f', 's'), ('f', 'd'), ('f', 'g'), ('f', 'h'), ('g', 'a'), ('g', 's'), ('g', 'd'), ('g', 'f'), ('g', 'h'), ('h', 'a'), ('h', 's'), ('h', 'd'), ('h', 'f'), ('h', 'g')) product(*iterables, repeat=1)
iterables: 可迭代对象,可以为多个
repeat: 可迭代对象的重复次数,也就是复制的次数
返回迭代器。生成可迭代对象的笛卡尔积, 类似于两个或多个可迭代对象的排列组合。与zip函数很像,但是zip是元素的一对一对应关系,而product则是一对多的关系。
from itertools import product list_data = [1, 2, 3] list_data2 = [4, 5, 6] print(list(product(list_data, list_data2))) print(list(zip(list_data, list_data2))) # 如下两个含义是一样的,都是将可迭代对象复制一份, 很方便的进行同列表的操作 print(list(product(list_data, repeat=2))) print(list(product(list_data, list_data))) # 同上述含义 print(list(product(list_data, list_data2, repeat=2))) print(list(product(list_data, list_data2, list_data, list_data2))) #输出 [(1, 4), (1, 5), (1, 6), (2, 4), (2, 5), (2, 6), (3, 4), (3, 5), (3, 6)] [(1, 4), (2, 5), (3, 6)] [(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)] [(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)] [(1, 4, 1, 4), (1, 4, 1, 5), (1, 4, 1, 6), (1, 4, 2, 4), (1, 4, 2, 5), (1, 4, 2, 6), (1, 4, 3, 4), (1, 4, 3, 5), (1, 4, 3, 6), (1, 5, 1, 4), (1, 5, 1, 5), (1, 5, 1, 6), (1, 5, 2, 4), (1, 5, 2, 5), (1, 5, 2, 6), (1, 5, 3, 4), (1, 5, 3, 5), (1, 5, 3, 6), (1, 6, 1, 4), (1, 6, 1, 5), (1, 6, 1, 6), (1, 6, 2, 4), (1, 6, 2, 5), (1, 6, 2, 6), (1, 6, 3, 4), (1, 6, 3, 5), (1, 6, 3, 6), (2, 4, 1, 4), (2, 4, 1, 5), (2, 4, 1, 6), (2, 4, 2, 4), (2, 4, 2, 5), (2, 4, 2, 6), (2, 4, 3, 4), (2, 4, 3, 5), (2, 4, 3, 6), (2, 5, 1, 4), (2, 5, 1, 5), (2, 5, 1, 6), (2, 5, 2, 4), (2, 5, 2, 5), (2, 5, 2, 6), (2, 5, 3, 4), (2, 5, 3, 5), (2, 5, 3, 6), (2, 6, 1, 4), (2, 6, 1, 5), (2, 6, 1, 6), (2, 6, 2, 4), (2, 6, 2, 5), (2, 6, 2, 6), (2, 6, 3, 4), (2, 6, 3, 5), (2, 6, 3, 6), (3, 4, 1, 4), (3, 4, 1, 5), (3, 4, 1, 6), (3, 4, 2, 4), (3, 4, 2, 5), (3, 4, 2, 6), (3, 4, 3, 4), (3, 4, 3, 5), (3, 4, 3, 6), (3, 5, 1, 4), (3, 5, 1, 5), (3, 5, 1, 6), (3, 5, 2, 4), (3, 5, 2, 5), (3, 5, 2, 6), (3, 5, 3, 4), (3, 5, 3, 5), (3, 5, 3, 6), (3, 6, 1, 4), (3, 6, 1, 5), (3, 6, 1, 6), (3, 6, 2, 4), (3, 6, 2, 5), (3, 6, 2, 6), (3, 6, 3, 4), (3, 6, 3, 5), (3, 6, 3, 6)] [(1, 4, 1, 4), (1, 4, 1, 5), (1, 4, 1, 6), (1, 4, 2, 4), (1, 4, 2, 5), (1, 4, 2, 6), (1, 4, 3, 4), (1, 4, 3, 5), (1, 4, 3, 6), (1, 5, 1, 4), (1, 5, 1, 5), (1, 5, 1, 6), (1, 5, 2, 4), (1, 5, 2, 5), (1, 5, 2, 6), (1, 5, 3, 4), (1, 5, 3, 5), (1, 5, 3, 6), (1, 6, 1, 4), (1, 6, 1, 5), (1, 6, 1, 6), (1, 6, 2, 4), (1, 6, 2, 5), (1, 6, 2, 6), (1, 6, 3, 4), (1, 6, 3, 5), (1, 6, 3, 6), (2, 4, 1, 4), (2, 4, 1, 5), (2, 4, 1, 6), (2, 4, 2, 4), (2, 4, 2, 5), (2, 4, 2, 6), (2, 4, 3, 4), (2, 4, 3, 5), (2, 4, 3, 6), (2, 5, 1, 4), (2, 5, 1, 5), (2, 5, 1, 6), (2, 5, 2, 4), (2, 5, 2, 5), (2, 5, 2, 6), (2, 5, 3, 4), (2, 5, 3, 5), (2, 5, 3, 6), (2, 6, 1, 4), (2, 6, 1, 5), (2, 6, 1, 6), (2, 6, 2, 4), (2, 6, 2, 5), (2, 6, 2, 6), (2, 6, 3, 4), (2, 6, 3, 5), (2, 6, 3, 6), (3, 4, 1, 4), (3, 4, 1, 5), (3, 4, 1, 6), (3, 4, 2, 4), (3, 4, 2, 5), (3, 4, 2, 6), (3, 4, 3, 4), (3, 4, 3, 5), (3, 4, 3, 6), (3, 5, 1, 4), (3, 5, 1, 5), (3, 5, 1, 6), (3, 5, 2, 4), (3, 5, 2, 5), (3, 5, 2, 6), (3, 5, 3, 4), (3, 5, 3, 5), (3, 5, 3, 6), (3, 6, 1, 4), (3, 6, 1, 5), (3, 6, 1, 6), (3, 6, 2, 4), (3, 6, 2, 5), (3, 6, 2, 6), (3, 6, 3, 4), (3, 6, 3, 5), (3, 6, 3, 6)]
repeat(object[, times])
object:任意合法对象
times: 可选,object对象生成的次数, 当不传入times,则无限循环
返回一个迭代器,根据times重复生成object对象。
from itertools import repeat str_data = "assd" print(repeat(str_data)) print(list(repeat(str_data, 4))) list_data = [1, 2, 4] print(repeat(list_data)) print(list(repeat(list_data, 4))) dict_data = {"a": 1, "b": 2} print(repeat(dict_data)) print(list(repeat(dict_data, 4))) #输出 repeat('assd') ['assd', 'assd', 'assd', 'assd'] repeat([1, 2, 4]) [[1, 2, 4], [1, 2, 4], [1, 2, 4], [1, 2, 4]] repeat({'a': 1, 'b': 2}) [{'a': 1, 'b': 2}, {'a': 1, 'b': 2}, {'a': 1, 'b': 2}, {'a': 1, 'b': 2}] starmap(function, iterable)
function: 作用域迭代器对象元素的函数
iterable: 可迭代对象
返回一个迭代器, 将函数作用与可迭代对象的所有元素(所有元素必须要是可迭代对象,即使只有一个值,也需要使用可迭代对象包裹,例如元组(1, ))中,与map函数类似;当function参数与可迭代对象元素一致时,使用元组代替元素,例如pow(a, b),对应的是[(2,3), (3,3)]。
map与starmap的区别在于,map我们一般会操作一个function只有一个参数的情况,starmap可以操作function多个参数的情况。
from itertools import starmap list_data = [1, 2, 3, 4, 5] list_data2 = [(1, 1), (2, 2), (3, 3), (4, 4), (5, 5)] list_data3 = [(1,), (2,), (3,), (4,), (5,)] print(list(starmap(lambda x, y: x + y, list_data2))) print(list(map(lambda x: x * x, list_data))) print(list(starmap(lambda x: x * x, list_data))) print(list(starmap(lambda x: x * x, list_data3))) #输出 [2, 4, 6, 8, 10] [1, 4, 9, 16, 25] Traceback (most recent call last): File "c:\Users\ts\Desktop\2022.7\2022.7.22\test.py", line 65, inprint(list(starmap(lambda x: x * x, list_data))) TypeError: 'int' object is not iterable
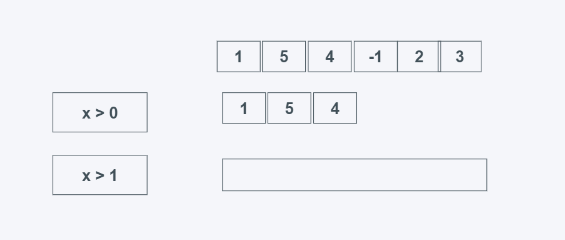
takewhile(predicate, iterable)
predicate:判断条件,为真就返回
iterable: 可迭代对象
当predicate为真时返回元素,需要注意的是,当第一个元素不为True时,则后面的无论结果如何都不会返回,找的前多少个为True的元素。
from itertools import takewhile #学习中遇到问题没人解答?小编创建了一个Python学习交流群:725638078 list_data = [1, 5, 4, 6, 2, 3] print(list(takewhile(lambda x: x > 0, list_data))) print(list(takewhile(lambda x: x > 1, list_data)))
zip_longest(*iterables, fillvalue=None)
iterables:可迭代对象
fillvalue:当长度超过时,缺省值、默认值, 默认为None
返回迭代器, 可迭代对象元素一一对应生成元组,当两个可迭代对象长度不一致时,会按照最长的有元素输出并使用fillvalue补充,是zip的反向扩展,zip为最小长度输出。
from itertools import zip_longest list_data = [1, 2, 3] list_data2 = ["a", "b", "c", "d"] print(list(zip_longest(list_data, list_data2, fillvalue="-"))) print(list(zip_longest(list_data, list_data2))) print(list(zip(list_data, list_data2))) [(1, 'a'), (2, 'b'), (3, 'c'), ('-', 'd')] [(1, 'a'), (2, 'b'), (3, 'c'), (None, 'd')] [(1, 'a'), (2, 'b'), (3, 'c')] 总结
accumulate(iterable: Iterable, func: None, initial:None):
进行可迭代对象元素的累计运算,可以设置初始值,类似于reduce,相比较reduce,accumulate可以输出中间过程的值,reduce只能输出最后结果,且accumulate性能略好于reduce。
chain(*iterables)
依次输出迭代器中的元素,不会循环输出,有多少输出多少。对于字典输出元素时,默认会输出字典的key;对于列表来说相当于是extend。
combinations(iterable: Iterable, r):
抽取可迭代对象的子序列,其实就是排列组合,不过只返回有序、不重复的子序列,以元组形式呈现。
combinations_with_replacement(iterable: Iterable, r)
抽取可迭代对象的子序列,与combinations类似,不过返回无序、不重复的子序列,以元组形式呈现。
compress(data: Iterable, selectors: Iterable)
根据selectors中的元素是否为True或者False返回可迭代对象的合法元素,selectors为str时,都为True,并且只会决定长度。
count(start, step):
从start开始安装step不断生成元素,是无限循环的,最好控制输出个数或者使用next(),send()等获取、设置结果
cycle(iterable)
依次输出可迭代对象的元素,是无限循环的,相当于是chain的循环。最好控制输出个数或者使用next(),send()等获取、设置结果。
dropwhile(predicate, iterable)
根据predicate是否为False来返回可迭代器元素,predicate可以为函数, 返回的是第一个False及之后的所有元素,不管后面的元素是否为True或者False。适用于需要舍弃迭代器或者可迭代对象的前面一部分内容,例如在写入文件时忽略文档注释

filterfalse(predicate, iterable)
依据predicate返回可迭代对象的所有predicate为True的元素,类似于filter方法。
groupby(iterable, key=None)
输出连续符合key要求的键值对,默认为x == x。
islice(iterable, stop)\islice(iterable, start, stop[, step])
对可迭代对象进行切片,和普通切片类似,但是这个不支持负数。适用于可迭代对象内容的切割,例如你需要获取一个文件中的某几行的内容
pairwise(iterable)
返回连续的重叠对象(两个元素), 少于两个元素返回空,不返回。
permutations(iterable, r=None)
从可迭代对象中抽取子序列,与combinations类似,不过抽取的子序列是无序、可重复。
product(*iterables, repeat=1)
输出可迭代对象的笛卡尔积,类似于排序组合,不可重复,是两个或者多个可迭代对象进行操作,当是一个可迭代对象时,则返回元素,以元组形式返回。
repeat(object[, times])
重复返回object对象,默认时无限循环
starmap(function, iterable)
批量操作可迭代对象中的元素,操作的可迭代对象中的元素必须也要是可迭代对象,与map类似,但是可以对类似于多元素的元组进行操作。
takewhile(predicate, iterable)
返回前多少个predicate为True的元素,如果第一个为False,则直接输出一个空。
zip_longest(*iterables, fillvalue=None)
将可迭代对象中的元素一一对应,组成元组形式存储,与zip方法类似,不过zip是取最短的,而zip_longest是取最长的,缺少的使用缺省值。
到此这篇关于一文详解Python中itertools模块的使用方法的文章就介绍到这了,更多相关Python itertools模块内容请搜索0133技术站以前的文章或继续浏览下面的相关文章希望大家以后多多支持0133技术站!
以上就是一文详解Python中itertools模块的使用方法的详细内容,更多请关注0133技术站其它相关文章!








