pfd文档一般无法直接去除水印,需要先将pfd文档转换成图片,在逐一对图片进行水印去除操作,最后在把图片插入到pdf文档中,这样就很繁琐。本文将用十行Python3代码轻轻松松实现PDF文件水印去除,快来了解一下吧
1、引言
小屌丝:鱼哥,最近有点不像话了。
小鱼:嗯?? 啥个意思嘛~
小屌丝:一周了,没分享小知识了。
小鱼:就因为这个??
小屌丝:那是,我这么爱学习的人。
小鱼:怕是你有什么事情解决不了,想到我了吧?
小屌丝:呵 ~ 笑话 ~ 我 能有…什…么…事情…
小鱼:说吧,
小屌丝:这可是你让我说的,我可没主动要问的!
小鱼:说吧,咋还磨磨唧唧了呢
小屌丝:我在某站下载的pfd文档,有水印,如何去掉啊?
小鱼:我突然想起来,PPT还没写完。
小屌丝:我家楼下刚开一个烧烤店,据说还不错!
小鱼:PPT写不完,可以晚上写,助人为乐让我更快乐。

2、代码实战
在上一篇博文,我们知道了如何给pdf文档添加水印,
而本篇,我们就给pdf去水印
如果不知道如何添加水印,就看这篇:2行Python代码实现给pdf文件添加水印
小屌丝:你这添加完水印,又去除水印,你这是闹哪样??
小鱼:我喜欢,我稀罕,我乐意!!
2.1 去除原理
去除方法:
1、用 PyMuPDF 打开 pdf 文件,将 pdf 的每一页都转换为图片 pixmap,
2、pixmap 有它自己的 RGB,只需要将 pdf 水印中的 RGB 改为(255, 255, 255),并保存图片
3、按照生成的图片,插入到pdf文档中
因为pfd文档无法直接去除水印,需要先将pfd文档转换成图片,在逐一对图片进行水印去除操作,最后在把图片插入到pdf文档中
2.2 代码解析
1、先查看PDF文档中的水印rgb值是多少

可以看到,RGB(179,179,179),因为这里要的是RGB色值总和,所以我们就认为,超过510,就认为是水印。
敲黑板
- 光学三原色是红绿蓝(RGB),也就是说它们是不可分解的三种基本颜色,其他颜色都可以通过这三种颜色混合而成,三种颜色等比例混合就是白色,没有光就是黑色。
- 在计算机中,可以用三个字节表示 RGB 颜色,1个字节能表示的最大数值是 255, 所以,(255, 0, 0)代表红色,(0, 255, 0)代表绿色,(0, 0, 255)代表蓝色。相应地,(255, 255, 255)代表白色,(0, 0, 0)代表黑色。从(0, 0, 0) ~ (255, 255, 255) 之间的任意组合都可以代表一个不同的颜色。
- 图片每个位置颜色由四元组表示,前三位分别是 RGB,第四位是 Alpha 通道
2、pdf转换成图片,并去除水印
代码示例:
# -*- coding:utf-8 -*- # @Time : 2022-02-23 # @Author : carl_DJ from PIL import Image from itertools import product import fitz # 去除pdf的水印 def remove_pdfwatermark(): #打开源pfd文件 pdf_file = fitz.open("跟小鱼学习去水印.pdf") #page_no 设置为0 page_no = 0 #page在pdf文件中遍历 for page in pdf_file: #获取每一页对应的图片pix (pix对象类似于我们上面看到的img对象,可以读取、修改它的 RGB) #page.get_pixmap() 这个操作是不可逆的,即能够实现从 PDF 到图片的转换,但修改图片 RGB 后无法应用到 PDF 上,只能输出为图片 pix = page.get_pixmap() #遍历图片中的宽和高,如果像素的rgb值总和大于510,就认为是水印,转换成255,255,255-->即白色 for pos in product(range(pix.width), range(pix.height)): if sum(pix.pixel(pos[0], pos[1])) >= 510: pix.set_pixel(pos[0], pos[1], (255, 255, 255)) #保存去掉水印的截图 pix.pil_save(f"./{page_no}.png-600", dpi=(30000, 30000)) #打印结果 print(f'第 {page_no} 页去除完成') page_no += 1 if __name__ == '__main__': remove_pdfwatermark()执行完成,
查看生成图片:
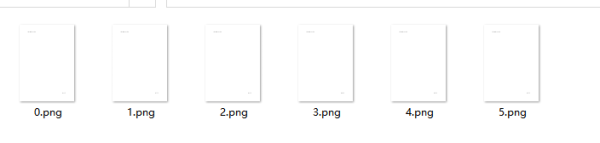
查看图片内容:

3、图片转为pdf
代码示例:
# -*- coding:utf-8 -*- # @Time : 2022-02-23 # @Author : carl_DJ from PIL import Image from itertools import product import fitz ''' 图片转为pdf''' #图片所在的文件夹 pic_dir = 'D:\Project\watemark' pdf = fitz.open() #图片数字文件先转换成int类型进行排序 img_files = sorted(os.listdir(pic_dir), key=lambda x: int(str(x).split('.')[0])) for img in img_files: print(img) imgdoc = fitz.open(pic_dir + '/' + img) #将打开后的图片转成单页pdf pdfbytes = imgdoc.convertToPDF() imgpdf = fitz.open("pdf", pdfbytes) #将单页pdf插入到新的pdf文档中 pdf.insertPDF(imgpdf) pdf.save("跟小鱼学习去水印_完成.pdf") pdf.close()执行代码,
查看生成的pdf文档
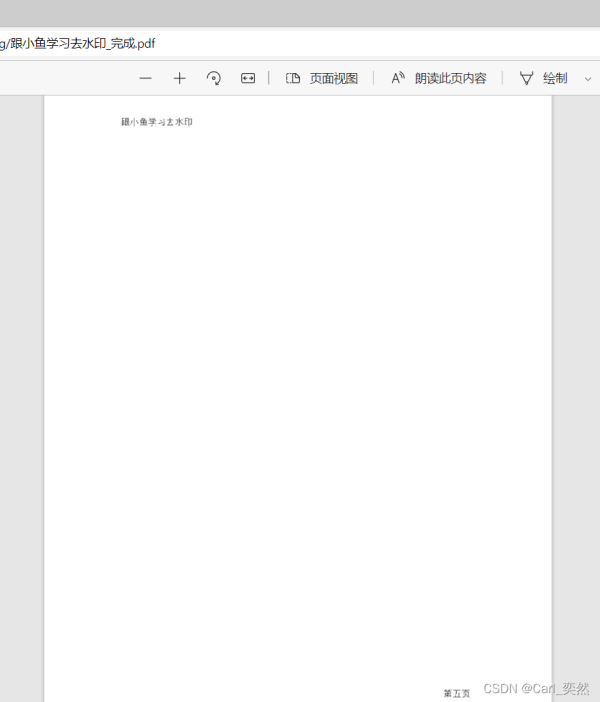
2.3 代码整合
上面的内容都了解以后,我们就整合代码,直接运行就可以了。
# -*- coding:utf-8 -*- # @Time : 2022-02-23 # @Author : carl_DJ from PIL import Image from itertools import product import fitz # 去除pdf的水印 def remove_pdfwatermark(): #打开源pfd文件 pdf_file = fitz.open("跟小鱼学习去水印.pdf") #page_no 设置为0 page_no = 0 #page在pdf文件中遍历 for page in pdf_file: #获取每一页对应的图片pix (pix对象类似于我们上面看到的img对象,可以读取、修改它的 RGB) #page.get_pixmap() 这个操作是不可逆的,即能够实现从 PDF 到图片的转换,但修改图片 RGB 后无法应用到 PDF 上,只能输出为图片 pix = page.get_pixmap() #遍历图片中的宽和高,如果像素的rgb值总和大于510,就认为是水印,转换成255,255,255-->即白色 for pos in product(range(pix.width), range(pix.height)): if sum(pix.pixel(pos[0], pos[1])) >= 510: pix.set_pixel(pos[0], pos[1], (255, 255, 255)) #保存去掉水印的截图 pix.pil_save(f"./{page_no}.png-600", dpi=(30000, 30000)) #打印结果 print(f'第 {page_no} 页去除完成') page_no += 1 #去除的pdf水印添加到pdf文件中 def pictopdf(): #水印截图所在的文件夹 # pic_dir = input("请输入图片文件夹路径:") pic_dir = 'D:\Project\watemark' pdf = fitz.open() #图片数字文件先转换成int类型进行排序 img_files = sorted(os.listdir(pic_dir), key=lambda x: int(str(x).split('.')[0])) for img in img_files: print(img) imgdoc = fitz.open(pic_dir + '/' + img) #将打开后的图片转成单页pdf pdfbytes = imgdoc.convertToPDF() imgpdf = fitz.open("pdf", pdfbytes) #将单页pdf插入到新的pdf文档中 pdf.insertPDF(imgpdf) pdf.save("跟小鱼学习去水印_完成.pdf") pdf.close() if __name__ == '__main__': remove_pdfwatermark() pictopdf()3、总结
写到这里,今天的分享就差不多快结束了。
需要理解的流程是,
1.pdf文档需要先转换成图片,进行水印去除,
2.再转换成pdf
3.最后插入到新的pdf文档中。
到此这篇关于十行Python3代码实现去除pdf文件水印的文章就介绍到这了,更多相关Python3去除pdf水印内容请搜索0133技术站以前的文章或继续浏览下面的相关文章希望大家以后多多支持0133技术站!
以上就是十行Python3代码实现去除pdf文件水印的详细内容,更多请关注0133技术站其它相关文章!








