机器学习是人工智能的核心,专门研究如何让计算机模拟和学习人类的行为。 深度学习是机器学习中的一个热门研究方向,它主要研究样本数据的内在规律和表示层次,让计算机能够让人一样具有分析与学习能力
机器学习
kNN算法
kNN算法将找出k个距离最近的邻居作为目标的 同一类别
图解kNN算法
使用OpenCV的ml模块中的kNN算法的基本步骤如下。
(1)调用cv2.mL.KNearest_ create()函数创建kNN分类器。
(2)将训练数据和标志作为输入,调用kNN分类器的train()方法训练模型。
(3)将待分类数据作为输入,调用kNN分类器的findNearest()方法找出K个最近邻居,返回 分类结果的相关信息。
下面的代码在图像中随机选择20个点,为每个点随机分配标志( 0或1 );图像中用矩形表示 标志0,用三角形表示标志1;再随机新增一个点,用kNN算法找出其邻居,并确定其标志(即完 成分类)。
import cv2 import numpy as np import matplotlib.pyplot as plt points = np. random. randint(0,100, (20,2)) #随机选择20个点 labels = np. random. randint(0,2,(20,1)) #为随机点随机分配标志 label0s = points[labels.ravel()==0] #分出标志为0的点 plt. scatter(label0s[:,0],label0s[:,1],80,'b','s') #将标志为0的点绘制为蓝色矩形 label1s = points[labels.ravel()==1] #分出标志为1的点 plt. scatter(label1s[:,0],label1s[:,1],80,'r','^') #将标志为1的点绘制为红色三角形 newpoint = np.random.randint(0,100,(1,2)) #随机选择一个点,下面确定其分类 plt.scatter(newpoint[:,0],newpoint[:,1],80,'g','o') #将待分类新点绘制为绿色圆点 plt.show() #进一步使用kNN算法确认待分类新点的类别、3个最近邻居和距离 knn = cv2.ml.KNearest_create() #创建kNN分类器 knn.train(points.astype(np.float32).cv2.ml.ROW_SAMPLE,labels.astype(np. float32)) #训练模型 ret,results,neighbours,dist = knn.findNearest(newpoint.astype(np.float32), 3) #找出3个最近邻居 print("新点标志: %s" % results) print("邻居: %s" % neighbours) print("距离: %s" % dist)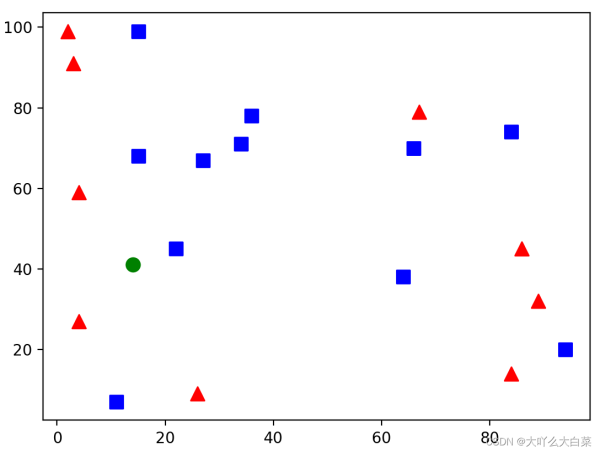
新点标志: [[1.]]
邻居: [[0. 1. 1.]]
距离: [[ 80. 296. 424.]]
因为三个最近邻居有两个是红色三角,所以他的标志为一
用kNN算法实现手写数字识别
用下列图片用来训练。
先把下面分割为每个数字大小都是20*20的图像,用于训练模型。
然后将手写的数字进行反二值化阈值处理转换成黑白图像,用像素值作为特征向量进行测试

import cv2 import numpy as np import matplotlib.pyplot as plt gray = cv2. imread('img/a.png-600',0) #读入手写数字的灰度图像 digits = [np.hsplit(r,100) for r in np.vsplit(gray,50)] #分解数字: 50行、100 列 np_digits = np.array(digits ) #转换为NumPy数组 #准备训练数据,转换为二维数组,每个图像400个像素 train_data = np_digits.reshape(-1, 400). astype(np. float32) train_labels = np.repeat(np. arange(10),500)[:,np.newaxis] #定义标志 knn = cv2.ml.KNearest_create() #创建kNN分类器 knn.train(train_data, cv2.ml.ROW_SAMPLE,train_labels) #训练模型 #用绘图工具创建的手写数字5图像(大小为20x 20 )进行测试 test= cv2.imread('img/a5.png-600',0) #打开图像 test_data=test.reshape(1,400).astype(np.float32) #转换为测试数据 ret,result,neighbours,dist = knn. findNearest(test_data,k=3) #执行测试 print(result.ravel()) #输出测试结果 print(neighbours.ravel()) #将对手写数字9拍摄所得图像的大小转换为20 x 20进行测试 img2=cv2. imread('img/d3.png-600',0) ret,img2=cv2. threshold(img2,150, 255, cv2. THRESH_BINARY_INV) #反二值化阈值处理 test_data=img2.reshape(1,400).astype(np. float32) #转换为测试数据 ret,result,neighbours,dist = knn. findNearest(test_data,k=3) #执行测试 print(result.ravel()) #输出测试结果 print(neighbours .ravel())用一张绘图图片和手写图片用来测试

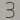
输出结果:
[5.]
[5. 5. 5.]
[3.]
[3. 5. 3.]
SVM算法
可使用一条直线将线性可分离的数据分为两组,这条直线在SVM算法中称为“决策边界”; 非线性可分离的数据转换为高维数据后可称为线性可分离数据。这是SVM算法的理论基础。
图解SVM算法
下面的代码在图像中选择了五个点,分为两类,类别标志分别为0和1。将五个点和标志作为已知分类数据训练SVM模型;然后用模型对图像中的所有点进行分类,根据分类结果设置图像颜色,从而直观显示图像像素的分类结果。
import cv2 import numpy as np import matplotlib.pyplot as plt#准备训练数据,假设图像高240,宽320,在其中选择5个点 traindata=np.matrix([[140,60],[80, 120],[16,10],[166,190],[248, 180]],dtype = np.float32) #5个点,前3个点为一类,标志为8;后2个点为一类,标志为1 labels = np.array([0,0,0,1,1]) svm = cv2.ml.SVM_create() #创建SVM分类器 svm. setGamma(0.50625) #设置相关参数 svm. setC(12.5) svm. setKernel(cv2.ml.SVM_LINEAR) svm.setType(cv2.ml.SVM_C_SVC) svm. setTermCriteria((cv2. TERM_CRITERIA_MAX_ITER, 100, 1e-6)) svm.train(traindata, cv2.ml. ROW_SAMPLE, labels) #训练模型 img = np.zeros((240,320,3),dtype="uint8" ) #创建图像 colors = {0:(102,255,204),1:(204,204,102)} #用SVM分类器对图像像素进行分类,根据分类结果设置像素颜色 for i in range(240): for j in range(320): point = np.matrix([[j,i]], dtype=np.float32) #将像素坐标转换为测试数据 label = svm.predict(point)[1].ravel() #执行预测,返回结果 img[i,j] = colors[label[0]] #根据预测结果设置像素颜色 svm_vectors = svm. getUncompressedSupportVectors() #获得SVM向量 for i in range(svm_vectors.shape[0]): #在图像中绘制SVM向量(红色圆) cv2.circle(img,(int(svm_vectors[i,0]),int(svm_vectors[i,1])),8,(0,0,255),2) #在图像中绘制训练数据点,类别标志0使用蓝色,类别标志1使用绿色 cv2.circle(img, (140, 60),5,(255,0,0),-1) cv2.circle(img, (80,120),5,(255,0,0),-1) cv2.circle(img, (160,110),5,(255,0,0),-1) cv2.circle(img, (160,190),5,(0,255,0),-1) cv2.circle(img, (240,180),5,(0,255,0),-1) img = cv2. cvtColor(img, cv2.COLOR_BGR2RGB) #转换为RGB格式 plt. imshow(img) plt. show() #显示结果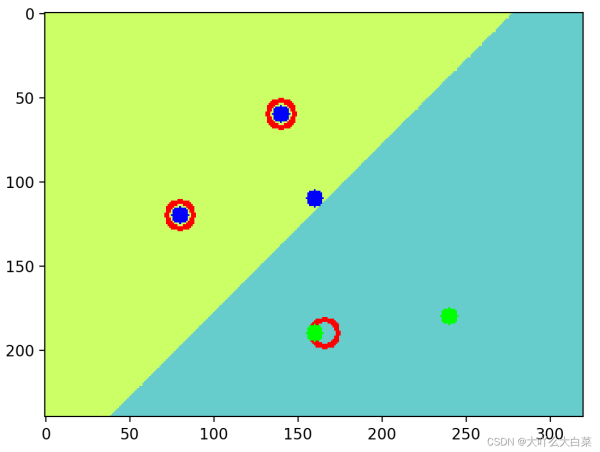
如图中三个蓝点为一类,下面两个训练点为一类,两颜色交界位置为决策边界
使用SVM算法识别手写数据
kMM算法使用了像素值作为特征向量。 svm算法可使用图像的定向梯度直方图作为特征向量来对图像进行分类 梯度直方图
用svm识别数字和knn的区别在于他会使用图像的定向梯度直方图作为特征向量来对图像进行分类。
下面代码步骤:
1.定义了HOG描述符的计算函数,用于将单个数字图像计算HOG描述符,再转换成一维数组(特征描述符就是通过提取图像的有用信息,并且丢弃无关信息来简化图像的表示)
2.分解图片,计算每张图片对应的HOG描述符
3.创建svm分类器,用这些图片进行训练模型
4.用绘制的图像测试
import cv2 import numpy as np def hog(img): #定义HOG描述符的计算函数 hog = cv2.HOGDescriptor((20,20),(8,8),(4,4),(8,8),9,1,-1,0,0.2,1,64,True) #定义HOGDescriptor对象 hog_descriptor=hog.compute(img) #计算HOG描述符 hog_descriptor=np.squeeze(hog_descriptor) #转换为一维数组 return hog_descriptor #返回HOG描述符,144 位 img = cv2.imread('img/a.png-600',0) digits=[np.hsplit(row,100) for row in np.vsplit(img, 50)] #分解图像,50行、100列 labels = np.repeat(np. arange(10),500)[:,np.newaxis] #定义对应的标记 hogdata = [list(map(hog,row)) for row in digits] #计算图像的HOG描述符 trainData = np. float32(hogdata) . reshape(-1, 144) #转换为测试数据 svm = cv2.ml.SVM_create( ) #创建SVM分类器 #设置相关参数 svm. setKernel(cv2.ml. SVM_LINEAR) svm. setType(cv2.ml.SVM_C_SVC) svm. setC(2.67) svm. setGamma(5.383) svm. train(trainData, cv2.ml. ROW_SAMPLE, labels) #训练模型 #用绘图工具创建的手写数字5图像(大小为20 x 20 )进行测试 test= cv2.imread('img/d5.jpg-600',0) #打开图像 test_data=hog(test) test_data=test_data.reshape(1, 144) . astype(np. float32) #转换为测试数据 result = svm. predict(test_data)[1] print( '识别结果: ',np. squeeze(result)) #用绘图工具创建的手写数字8图像(大小为20 x20 )进行测试 test= cv2. imread('img/d7.jpg-600' ,0) test_data=hog(test) test_data=test_data.reshape(1,144).astype(np .float32) #转换为测试数据 result = svm. predict(test_data)[1] print('识别结果:',np.squeeze(result))k均值聚类算法
k均值聚类算法的基本原理是根据数据的密集程度寻找相对密集数据的质心,再根据质心完成数据分类
图解k均值聚类算法
下面代码在大小为240*320的图像中选择3组数据点,不同颜色显示分类数据和质心
import cv2 import numpy as np from matplotlib import pyplot as plt #创建聚类数据,3个类别,每个类别包含20个点 data = np.vstack((np.random. randint(10,90, (20,2)),np. random. randint(80,170, (20, 2)),np.random.randint(160,250, (20, 2)))) data=data.astype(np.float32) #定义算法终止条件 criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 20, 1.0) #使用k均值聚类算法执行分类操作,k=3,返回结果中label用于保存标志,center 用于保存质心 ret,label,center=cv2. kmeans(data,3,None, criteria,10,cv2.KMEANS_RANDOM_CENTERS) #根据运算结果返回的标志将数据分为3组,便于绘制图像 data1 = data[label.ravel() == 0] data2 = data[label.ravel() == 1] data3 = data[label.ravel() == 2] plt. scatter(data1[:,0], data1[:,1], c='r') #绘制第1类数据点,红色 #绘制第2类数据点,绿色 plt.scatter(data2[:,0],data2[:,1],c='g') #绘制第3类数据点,蓝色 plt.scatter(data3[:,0], data3[:,1], c='b') plt.scatter(center[:,0],center[:,1],100,['#CC3399'],'s') #绘制质心,颜色为#CC3399 #显示结果 plt. show()
使用k均值聚类算法量化图像颜色
使用k均值聚类算法量化图像颜色,即将质心作为图像新的像素,从而减少图像中的颜色值 K均值聚类步骤:
第一步:确定K值,聚类成K个类簇。
第二步:从数据中随机选择(或按照某种方式)K个数据点作为初始分类的中心。
第三步:分别计算数据中每个点到每个中心的距离,将每个点划分到离中心最近的类中
第四步:当每个中心都划分了一些点后,去每个类的均值,选出新的中心。
第五步:比较新的中心和之前的中心,如果新的中心和之前的中心之间的距离小于某阈值,或迭代次数超过某阈值,认为聚类已经收敛,终止。
第六步:否则继续迭代执行第三到五步,直到第五步满足。
import cv2 import numpy as np img = cv2.imread('img/qwe.jpg-600') #打开图像 #显示原图 img2 = img.reshape((-1,3)). astype(np. float32) #转换为nx 3的浮点类型数组,n=图像像素的总数一3 #定义算法终止条件 criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0) K=8 ret,label,center=cv2.kmeans(img2,K,None, criteria,10,cv2.KMEANS_RANDOM_CENTERS) center = np.uint8(center) #将质心转换为整型 img3 = center[label.ravel()] #转换为一维数组 img3 = img3.reshape((img.shape)) #恢复为原图像数组形状 cv2.imshow('K=8',img3) K=12 ret,label,center=cv2. kmeans(img2,K,None, criteria,10,cv2.KMEANS_RANDOM_CENTERS) center = np.uint8(center) #将质心转换为整型 img3 = center[label.ravel()] #转换为一维数组 img3 = img3.reshape((img.shape)) #恢复为原图像数组形状 cv2.imshow('K=12',img3) cv2.waitKey(0)- 将原图的二维(宽,高)三通道的图片转换成了一维(一列)三通道的数组
- 根据误差和迭代次数定义算法终止的条件
- 将一维三通道的值根据K分成的类别替换为质心的值
- 将这个数组再转换为原图像的数组形状
下图分别是原图、k=4、k=8、k=12的图


深度学习
机器学习通常包含输入、特征提取、分类和输出四个步骤
深度学习通常分为输入、特征提取与分类和输出3个步骤,它将机器学习中的特征提取和分类和并在同一个步骤中完成
基于深度学习的图像识别
图像识别是将图像内容作为一个对象来识别其类型。使用OpenCV中的深度学习预训练模型进行图像识别的基本步骤如下。
- 从配置文件和预训练模型文件中加载模型。
- 将图像文件处理为块数据( blob )。
- 将图像文件的块数据设置为模型的输入。
- 执行预测。
- 处理预测结果。
基于AlexNet和Caffe模型进行图像识别
1.从文本中获取每个类别的名称
2.载入Caffe模型
3.打开用于识别分类的图像
4.创建图像块数据,将图像块数据作为神经网络输入
5.执行预测,返回的是一个1*1000的数组,是按照顺序对应1000种类别的可信度
6.输出排名第一的预测结果
import cv2 import numpy as np from matplotlib import pyplot as plt from PIL import ImageFont,ImageDraw, Image #读入文本文件中的类别名称,共0种类到每行为一个类到,从第11个字符开始为名称 #基本格式如下 # n01440764 tench, Tinca tinca # n01443537 goldfish, Carassius auratus file=open('classes.txt' ) names=[r.strip() for r in file.readlines()] file.close() classes = [r[10:] for r in names] #获取每个类别的名称 #从文件中载入Caffe模型 net = cv2.dnn.readNetFromCaffe("AlexNet_deploy.txt", "AlexNet_CaffeModel.dat") image = cv2. imread("img/qwe.jpg-600") #打开图像,用于识别分类 #创建图像块数据,大小为(224,224),颜色通道的均值缩减比例因子为(104, 117, 123) blob = cv2.dnn. blobFromImage(image, 1, (224,224), (104, 117, 123)) net. setInput(blob) #将图像块数据作为神经网络输入 #执行预测,返回结果是一个 1x 1000的数组,按顺序对应1000种类别的可信度 result = net. forward() ptime, x = net. getPerfProfile() #获得完成预测时间 print('完成预测时间: %.2f ms' % (ptime * 1000.0 / cv2.getTickFrequency(0))) sorted_ret = np. argsort(result[0]) #将预测结果按可信度由高到低排序 top5 = sorted. ret[::-1][:5] #获得排名前5的预测结果 ctext = "类别: "+classes[top5[0]] ptext = "可信度: {:.2%}" . format(result[0][top5[0]]) #输出排名前5的预测结果 for (index, idx) in enumerate(top5): print("t).类别: {},可信度: (:2%)" .format(index + 1, classes[idx], result[0][idx])) #在图像中输出排名第1的预测结果 fontpath = "STSONG. TTF" font = ImageFont . truetype( fontpath, 80) #载入中文字体,设置字号 img_pil = Image. fromarray(image) draw = ImageDraw.Draw(img_pil) draw.text((10, 10),ctext, font = font,fill=(0,0,255)) #绘制文字 draw.text((10,100),ptext, font = font, fill=(0,0,255)) img = np.array(img_pil) img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB) plt.imshow(img) plt.axis('off') plt.show()
基于深度学习的对象检测
对象检测是指检测出图像中的所有对象。并识别对象的类型。使用OpenCV中的深度学习预训练模型进行对象检测的基本步骤如下。
- 从配置文件和预训练模型文件中加载模型。
- 创建图像文件的块数据( blob )。
- 将图像文件的块数据设置为模型的输入。
- 执行预测。
- 处理预测结果。
基于YOLO和Darknet预训练模型的对象检测
1.从文本中获取每个类别的名称
2.载入预训练的Darknet模型
3.打开用于对象检测的图像
4.创建图像块数据,将图像块数据作为神经网络输入
5.执行预测,返回每层的预测结果
6.遍历所有的输出层,遍历层的所有输出预测结果,每个结果为一个边框
7.筛选出概率大于50%的类别,获取他们的坐标
8.用非最大值抑制获得要绘制的box(为最大值一直是为了消除重复边框)
9.绘制边框
import cv2 import numpy as np from matplotlib import pyplot as plt import matplotlib from PIL import InageFont, Inagoraw, Image #加载字体,以便显示汉字 fontpath = "STSONG.TTF” font = ImageFont.truetype(fontpath,20) #载入字体,设置字号 font2 = {'family': 'STSONG', "size": 22} matplotlib.rc('font', **font2) #设置plt字体 #从文件中加载已知的对象名称,文件保存了80个类别的对象名称,每行个 f=open(" object_names .txt",encoding=' utf-8') object. names = [r.strip() for r in f.readlines()] f.close() #从文件中加载预训练的Darknet模型 mode = cv2. dnn. readNetFromDarknet("yolov3.cfg", "yolov3.weights") image = cv2. imread(" objects. jpg") #打开图像文件 imgH, imgW = image . shape[ :2] ut_layers = mode. getLayerNames() #获得输出层 out_layers = [out_layers[i[0] - 1] for i in mode.getUnconnectedOutLayers()] blob = cv2.dnn. blobFromImage(image, 1/255.0, (416,416),swapRB=True, crop=False) #创建图像块数据 mode . setInput(blob) #将图像块数据设置为模型输入 layer_results = mode . forward(out_layers) #执行预测,返回每层的预测结果 ptime,_ = mode. getPerfProfile() tilte_text='完成预测时间: %.2f ms' % (ptime* 1000/cv2. getTickFrequency()) result_boxes = [] result_scores = [] result_name_id = [] for layer in layer_results: #遍历所有输出层 for box in layer: #遍历层的所有输出预测结果,每个结果为一个边框 #预测结果结构: x, y, w, h, confidence, 80 个类别的概率 probs = box[5:] class_id = np.argmax(probs) #找到概率最大的类别名称 prob = probs[class_id] #找到最大的概率 if prob > 0.5: #筛选出概率大于50%的类别 #计算每个box在原图像中的绝对坐标 box = box[0:4]* np.array[imgW, imgH, imgW, imgH]) (centerx, centery, width, heignt) = box.astype("int") x = int(centerX - (width / 2)) y = int(centerY - (height / 2)) result_boxes.append([x, y, int(width),int(height)]) result_scores . append(float(prob)) result_name_id. append(class_id) #应用非最大值抑制消除重复边框,获得要绘制的box draw_boxes = cv2.dnn. NMSBoxes(result_boxes, result_scores, 0.6, 0.3) if len(draw_boxes) > 0: for i in draw_boxes.ravel(): #获得边框坐标 (x, y) = (result_boxes[i][0], result_boxes[i][1]) (w, h) = (result_boxes[i][2], result_boxes[i][3]) #绘制边框 cv2.rectangle(image,(x,y), (x+w,y+h),(0,255,0),1) #输出类别名称和可信度 text=object_names[result_name_id[i]] +"\n{: .1%}". format(result_scores[i]) img_pil = Image.fromarray(image) draw = ImageDraw.Draw(img_pil) draw.text((x+5,y), text, font = font,fill=(0,0,255)) #绘制文字 image = np.array(img_pil) img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) plt. title(tilte_text) plt. imshow(img) plt.axis('off') plt. show()
到此这篇关于opencv深入浅出了解机器学习和深度学习的文章就介绍到这了,更多相关opencv 机器学习 内容请搜索0133技术站以前的文章或继续浏览下面的相关文章希望大家以后多多支持0133技术站!
以上就是opencv深入浅出了解机器学习和深度学习的详细内容,更多请关注0133技术站其它相关文章!








