这篇文章主要介绍了最新hadoop安装教程(亲测可用),本文主要讲解了如何安装hadoop、使用hadoop的命令及遇到的问题解决,需要的朋友可以参考下
01 引言
最近安装hadoop-2.7.7 版本的时候遇到了很多坑,本文来详细讲解如何安装和解决遇到的问题。
02 hadoop 安装
2.1 下载与安装
Step1: 下载
百度网盘下载
链接: https://pan.baidu.com/s/1ydPDP3xL0iL6sKYxdiq2ew 提取码: nnpf
Step2: 上传并解压
cd /data tar -zxvf hadoop-2.7.7.tar.gz
2.2 hadoop配置
Step1: 修改hadoop安装目录/etc/hadoop下的hadoop-env.sh的文件内容
[root@server11 hadoop]# vi hadoop-env.sh # 指定JAVA_HOME export JAVA_HOME=/usr/lib/jvm/TencentKona-8.0.1-242
Step2: 修改hadoop安装目录/etc/hadoop下的core-site.xml的文件内容
[root@server19 hadoop]# vi core-site.xmlfs.defaultFS hdfs://服务器的真实ip:9002 hadoop.tmp.dir /data/hadoop/tmp
注:这里fs.defaultFS的value最好是写本机的静态IP。当然写本机主机名,再配置hosts是最好的,如果用localhost,然后在windows用java操作hdfs的时候,会连接不上主机。
Step3: 修改hadoop安装目录/etc/hadoop下的hdfs-site.xml的文件内容
dfs.namenode.name.dir /data/hadoop/hadoop/hdfs/nn fs.checkpoint.dir /data/hadoop/hdfs/snn fs.checkpoint.edits.dir /data/hadoop/hdfs/snn dfs.datanode.data.dir /data/hadoop/hdfs/dn dfs.name.dir /data/hadoop/name dfs.data.dir /data/hadoop/node dfs.replication 1 dfs.http.address 服务器的真实ip:9000 ipc.maximum.data.length 134217728
*Step4: 修改hadoop安装目录/etc/hadoop下的yarn-site.xml的文件内容
yarn.nodemanager.vmem-check-enabled false yarn.nodemanager.aux-services mapreduce_shuffle yarn.application.classpath /data/hadoop-2.7.7/etc/*, /data/hadoop-2.7.7/etc/hadoop/*, /data/hadoop-2.7.7/lib/*, /data/hadoop-2.7.7/share/hadoop/common/*, /data/hadoop-2.7.7/share/hadoop/common/lib/*, /data/hadoop-2.7.7/share/hadoop/mapreduce/*, /data/hadoop-2.7.7/share/hadoop/mapreduce/lib/*, /data/hadoop-2.7.7/share/hadoop/hdfs/*, /data/hadoop-2.7.7/share/hadoop/hdfs/lib/*, /data/hadoop-2.7.7/share/hadoop/yarn/*, /data/hadoop-2.7.7/share/hadoop/yarn/lib/*
2.3 免登陆配置
线上环境已配置,无需配置
#到 root 目录下: cd /root #执行生成密钥命令: ssh-keygen -t rsa #然后三个回车 #然后复制公钥追加到第一台节点的公钥文件中: ssh-copy-id -i /root/.ssh/id_rsa.pub root@master01 #选择 yes #输入登录第一台节点的密码(操作完成该节点公钥复制到第一台节点中)
2.4 配置环境变量
vi /etc/profile ### 配置内容如下: export JAVA_HOME=/usr/lib/jvm/TencentKona-8.0.1-242 export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export HADOOP_HOME=/data/hadoop-2.7.7 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_CLASSPATH=`hadoop classpath` export HADOOP_CONF_DIR=/data/hadoop-2.7.7/etc/hadoop ### 生效配置 source /etc/profile
注意:配置HADOOP_CLASSPATH!
2.5 配置域名
可能会配置到,根据提示错误配置就好了
vi /etc/hosts 127.0.0.1 localhost.localdomain localhost 127.0.0.1 localhost4.localdomain4 localhost4 127.0.0.1 VM-xx-centos gp-master ::1 VM-xx-centos VM-xxx-centos ::1 localhost.localdomain localhost ::1 localhost6.localdomain6 localhost6 服务器的真实ip VM-xxx-centos localhost.localdomain gp-master
2.6 启动
进入hadoop安装目录/sbin,执行start-all.sh文件:
./start-all.sh
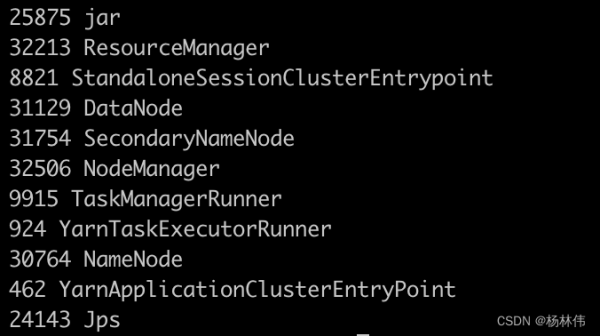
使用jps命令验证是否已经启动成功(这些都启动了才算成功:ResourceManager、DataNode、SecondaryNameNode、NodeManager、TaskManagerRunner、YarnTaskExecutorRunner、NameNode):
jps
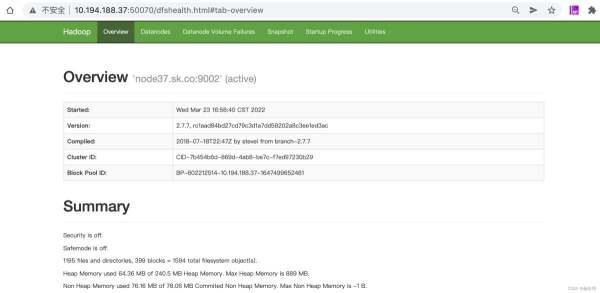
浏览器打开:http://服务器地址:50070/,可以看到hadoop环境搭建好了:
03 相关命令
3.1 yarn相关命令
## 正在运行的任务 yarn application -list ## kill掉yarn正在运行的任务 yarn application -kill application_1654588814418_0003 ## 查找yarn已经完成的任务列表 yarn application -appStates finished -list ## 查找yarn所有任务列表 yarn application -appStates ALL -list ## 查看容器日志 curl http://127.0.0.1:8042/node/containerlogs/container_1654588814418_0003_01_000001/root/jobmanager.out/?start=0 ## 查看yarn内存使用情况 curl http://127.0.0.1:8042/cluster
3.2 hdfs相关命令
# 因为在 HDFS 上没有为当前用户创建主目录,所以要先创建目录 $ hadoop fs -mkdir -p /user/root # 目录只能一级级创建 ,不能一下子创建2个 $ hadoop fs -mkdir ./flink # 上传 $ hadoop fs -put /资源路径/相关资源 ./flink # 下载 $ hadoop fs -get ./flink # 查看 $ hadoop fs -ls ./flink # 删除整个文件夹 $ hadoop fs -rm -rf flink # 此处为逐级删除 $ hadoop fs -rm ./flink/资源 # 备注:上面的 `./bin/hadoop fs`等同于`./bin/hdfs dfs`
04 一次填完所有的坑
1. 程序访问hdfs失败,提示“Failed on local exception: com.google.protobuf.InvalidProtocolBufferException: Protocol message”
解决方案:使用命令hdfs getconf -confKey fs.default.name获取正确的端口号并配置到程序
2. 首次安装hadoop,使用hdfs命令时,会提示“‘.’: No such file or directory”
解决方案: 因为在 hdfs 上没有为当前用户创建主目录,所以要先创建目录$ hadoop fs -mkdir -p /user/root
3. 首次安装hadoop,使用hdfs命令时,可能会提示“‘There are 0 datanode(s) running and no node(s) are excluded in this operation.”
解决方案:可能是格式化两次hadoop,导致没有datanode。首先stop-all.sh停掉所有的服务,然后找到hadoop指定的data目录(线上是:/data/hadoop)删除,接着从新执行一下 hadoop namenode -format,最后使用start-all.sh 重启一下hadoop
4. 使用hdfs命令,提示“Caused by: org.apache.hadoop.ipc.RemoteException: Cannot create directory”
解决方案:是因为安全模式没有自动关闭,使用命令关闭“hdfs dfsadmin -safemode leave”,然后删除出错的block块,命令:“hdfs fsck / -delete”。
5. 启动hadoop时,可能会提示second node connection refuesd,即访问被拒绝
解决方案: 修改hadoop安装目录/etc/hadoop下的hdfs-site.xml的文件内容
dfs.http.address 11.41.140.96:9002 dfs.secondary.http.address 11.41.140.96:9002
6.部署的时候可能会失败,提示 Failed on local exception: com.google.protobuf.InvalidProtocolBufferException: Protocol message,指的是端口号配置错了,查询端口号的命令:
解决方案:修改查询端口号并修改
hdfs getconf -confKey fs.default.name
7.hadoop的日志在哪个目录:
在:/data/hadoop-2.7.7/logs 05 Yarn相关配置
本文顺带讲下yarn相关的配置(在/etc/hadoop/yarn-site.xml配置),可以直接跳过。
| 配置 | 描述 |
|---|---|
yarn.nodemanager.resource.memory-mb | 表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。 |
yarn.nodemanager.vmem-pmem-ratio | 任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1。 |
yarn.nodemanager.pmem-check-enabled | 是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。 |
yarn.nodemanager.vmem-check-enabled | 是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。 |
yarn.scheduler.minimum-allocation-mb | 单个任务可申请的最少物理内存量,默认是1024(MB),如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数。 |
yarn.scheduler.maximum-allocation-mb | 单个任务可申请的最多物理内存量,默认是8192(MB)。 |
06 文末
本文主要讲解了如何安装hadoop、使用hadoop的命令及遇到的问题解决,希望能帮助到大家,谢谢大家的阅读,本文完!
以上就是最新hadoop安装教程及hadoop的命令使用(亲测可用)的详细内容,更多请关注0133技术站其它相关文章!







