这篇文章主要介绍了hadoop分布式环境搭建过程,本文图文并茂给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下
1. Java安装与环境配置
Hadoop是基于Java的,所以首先需要安装配置好java环境。从官网下载JDK,我用的是1.8版本。 在Mac下可以在终端下使用scp命令远程拷贝到虚拟机linux中。
danieldu@daniels-MacBook-Pro-857 ~/Downloads scp jdk-8u121-linux-x64.tar.gz root@hadoop100:/opt/software root@hadoop100's password: danieldu@daniels-MacBook-Pro-857 ~/Downloads
其实我在Mac上装了一个神器-Forklift。 可以通过SFTP的方式连接到远程linux。然后在操作本地电脑一样,直接把文件拖过去就行了。而且好像配置文件的编辑,也可以不用在linux下用vi,直接在Mac下用sublime远程打开就可以编辑了 :)
然后在linux虚拟机中(ssh 登录上去)解压缩到/opt/modules目录下
[root@hadoop100 include]# tar -zxvf /opt/software/jdk-8u121-linux-x64.tar.gz -C /opt/modules/
然后需要设置一下环境变量, 打开 /etc/profile, 添加JAVA_HOME并设置PATH用vi打开也行,或者如果你也安装了类似forklift这样的可以远程编辑文件的工具那更方便。
vi /etc/profile
按shift + G 跳到文件最后,按i切换到编辑模式,添加下面的内容,主要路径要搞对。
#JAVA_HOME export JAVA_HOME=/opt/modules/jdk1.8.0_121 export PATH=$PATH:$JAVA_HOME/bin
按ESC , 然后 :wq存盘退出。
执行下面的语句使更改生效
[root@hadoop100 include]# source /etc/profile
检查java是否安装成功。如果能看到版本信息就说明安装成功了。
[root@hadoop100 include]# java -version java version "1.8.0_121" Java(TM) SE Runtime Environment (build 1.8.0_121-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode) [root@hadoop100 include]#
2. Hadoop安装与环境配置
Hadoop的安装也是只需要把hadoop的tar包拷贝到linux,解压,设置环境变量.然后用之前做好的xsync脚本,把更新同步到集群中的其他机器。如果你不知道xcall、xsync怎么写的。可以翻一下之前的文章。这样集群里的所有机器就都设置好了。
[root@hadoop100 include]# tar -zxvf /opt/software/hadoop-2.7.3.tar.gz -C /opt/modules/ [root@hadoop100 include]# vi /etc/profile 继续添加HADOOP_HOME #JAVA_HOME export JAVA_HOME=/opt/modules/jdk1.8.0_121 export PATH=$PATH:$JAVA_HOME/bin #HADOOP_HOME export HADOOP_HOME=/opt/modules/hadoop-2.7.3 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin [root@hadoop100 include]# source /etc/profile 把更改同步到集群中的其他机器 [root@hadoop100 include]# xsync /etc/profile [root@hadoop100 include]# xcall source /etc/profile [root@hadoop100 include]# xsync hadoop-2.7.3/
3. Hadoop分布式配置
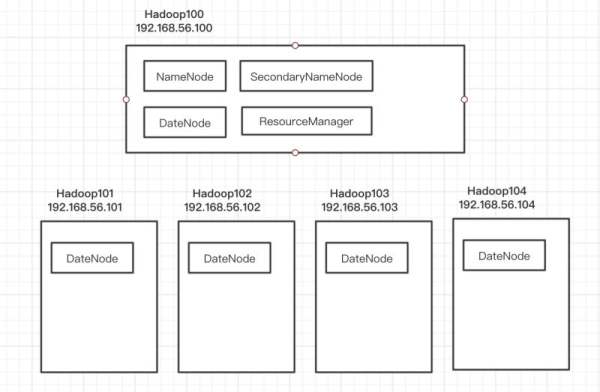
然后需要对Hadoop集群环境进行配置。对于集群的资源配置是这样安排的,当然hadoop100显得任务重了一点 :)
编辑0/opt/modules/hadoop-2.7.3/etc/hadoop/mapred-env.sh、yarn-env.sh、hadoop-env.sh 这几个shell文件中的JAVA_HOME,设置为真实的绝对路径。
export JAVA_HOME=/opt/modules/jdk1.8.0_121
打开编辑 /opt/modules/hadoop-2.7.3/etc/hadoop/core-site.xml, 内容如下
fs.defaultFS hdfs://hadoop100:9000 hadoop.tmp.dir /opt/modules/hadoop-2.7.3/data/tmp
编辑/opt/modules/hadoop-2.7.3/etc/hadoop/hdfs-site.xml, 指定让dfs复制5份,因为我这里有5台虚拟机组成的集群。每台机器都担当DataNode的角色。暂时也把secondary name node也放在hadoop100上,其实这里不太好,最好能和主namenode分开在不同机器上。
dfs.replication 5 dfs.namenode.secondary.http-address hadoop100:50090 dfs.permissions false
YARN 是hadoop的集中资源管理服务,放在hadoop100上。 编辑/opt/modules/hadoop-2.7.3/etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.hostname hadoop100 yarn.log-aggregation-enbale true yarn.log-aggregation.retain-seconds 604800
为了让集群能一次启动,编辑slaves文件(/opt/modules/hadoop-2.7.3/etc/hadoop/slaves),把集群中的几台机器都加入到slave文件中,一台占一行。
hadoop100
hadoop101
hadoop102
hadoop103
hadoop104
最后,在hadoop100上全部做完相关配置更改后,把相关的修改同步到集群中的其他机器
xsync hadoop-2.7.3/
在启动Hadoop之前需要format一下hadoop设置。
hdfs namenode -format
然后就可以启动hadoop了。从下面的输出过程可以看到整个集群从100到104的5台机器都已经启动起来了。通过jps可以查看当前进程。
[root@hadoop100 sbin]# ./start-dfs.sh Starting namenodes on [hadoo以上就是hadoop分布式环境搭建过程的详细内容,更多请关注0133技术站其它相关文章!







